
Is it feasible to run HPC in the cloud? How different is it from running a local HPC cluster? What are some of the common alternatives for running HPC in the cloud?
Introduction
Before beginning our discussion about HPC (High Performance Computing) in the cloud, let us talk about what exactly HPC really means?
“High Performance Computing most generally refers to the practice of aggregating computing power in a way that delivers much higher performance than one could get out of a typical desktop computer or workstation in order to solve large problems in science, engineering, or business.” (https://www.usgs.gov/core-science-systems/sas/arc/about/what-high-performance-computing)
In more technical terms – it refers to a cluster of machines composed of multiple cores (either physical or virtual cores), a lot of memory, fast parallel storage (for read/write) and fast network connectivity between cluster nodes.
HPC is useful when you need a lot of compute resources, from image or video rendering (in batch mode) to weather forecasting (which requires fast connectivity between the cluster nodes).
The world of HPC is divided into two categories:
Loosely coupled
In this scenario you might need a lot of compute resources, however, each task can run in parallel and is not dependent on other tasks being completed. Common examples of loosely coupled scenarios: Image processing, genomic analysis, etc.
Tightly coupled
In this scenario you need fast connectivity between cluster resources (such as memory and CPU), and each cluster node depends on other nodes for the completion of the task. Common examples of tightly coupled scenarios: Computational fluid dynamics, weather prediction, etc.
Pricing considerations
Deploying an HPC cluster on premise requires significant resources. This includes a large investment in hardware (multiple machines connected in the cluster, with many CPUs or GPUs, with parallel storage and sometimes even RDMA connectivity between the cluster nodes), manpower with the knowledge to support the platform, a lot of electric power, and more.
Deploying an HPC cluster in the cloud is also costly. The price of a virtual machine with multiple CPUs, GPUs or large amount of RAM can be very high, as compared to purchasing the same hardware on premise and using it 24×7 for 3-5 years.
The cost of parallel storage, as compared to other types of storage, is another consideration.
The magic formula is to run HPC clusters in the cloud and still have the benefits of (virtually) unlimited compute/memory/storage resources is to build dynamic clusters.
We do this by building the cluster for a specific job, according to the customer’s requirements (in terms of number of CPUs, amount of RAM, storage capacity size, network connectivity between the cluster nodes, required software, etc.). Once the job is completed, we copy the job output data and take down the entire HPC cluster in-order to save unnecessary hardware cost.
Alternatives for running HPC in the cloud
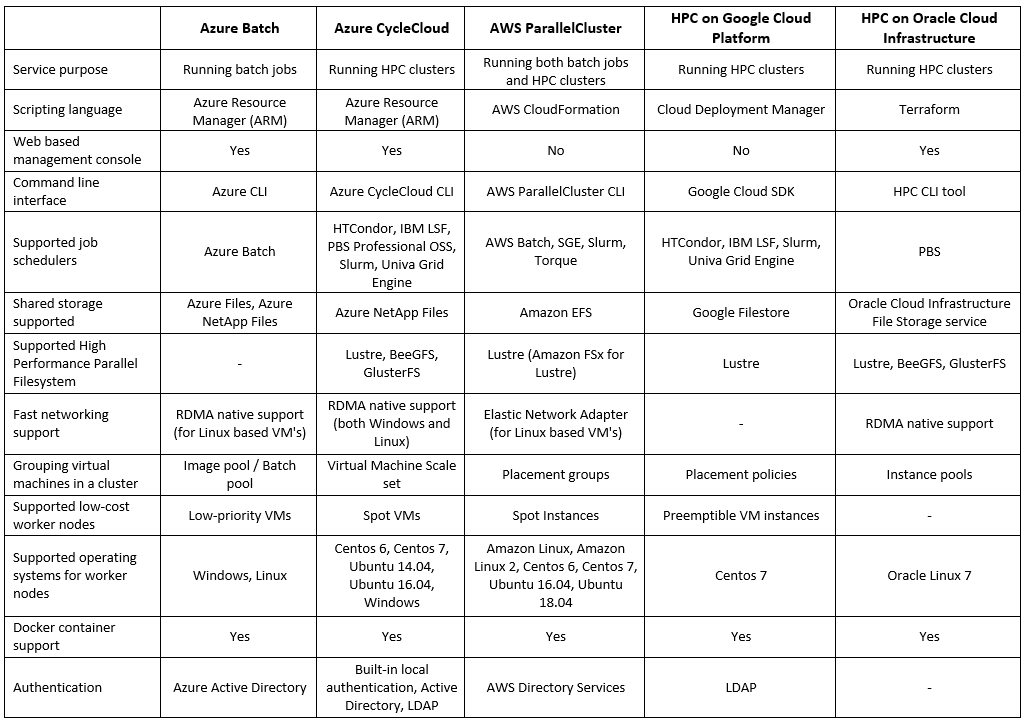
Summary
As you can see, running HPC in the public cloud is a viable option. But you need to carefully plan the specific solution, after gathering the customer’s exact requirements in terms of required compute resources, required software and of course budget estimation.
Product documentation
- Azure CycleCloud
https://azure.microsoft.com/en-us/features/azure-cyclecloud/
- AWS ParallelCluster
https://aws.amazon.com/hpc/parallelcluster/
- Slurm on Google Cloud Platform
https://github.com/SchedMD/slurm-gcp
- HPC on Oracle Cloud Infrastructure
https://www.oracle.com/cloud/solutions/hpc.html